今天 (2/4) 的 Daily 是 hard 題: 76. Minimum Window Substring
目錄
題目分析
題目
Given two strings s and t of lengths m and n respectively, return the minimum Window substring of s such that every character in t (including duplicates) is included in the Window. If there is no such substring, return the empty string “”.
給你一個字串s、一個字串t。傳回s中涵蓋t所有字元的最小子字串。如果s中不存在涵蓋t所有字元的子字串,則傳回空字串""。
對於t中重複字符,我們尋找的子字串中該字符數量必須不少於t中該字符數量。
The testcases will be generated such that the answer is unique.
如果s中存在這樣的子字串,我們保證它是唯一的答案。
Example 1:
Input: s = "ADOBECODEBANC", t = "ABC"
Output: "BANC"
Explanation: The minimum Window substring "BANC" includes 'A', 'B', and 'C' from string t.
Example 2:
Input: s = "a", t = "a"
Output: "a"
Explanation: The entire string s is the minimum Window.
Example 3:
Input: s = "a", t = "aa"
Output: ""
Explanation: Both 'a's from t must be included in the Window.
Since the largest Window of s only has one 'a', return empty string.
Constraints:
m == s.length
n == t.length
1 <= m, n <= 105
s and t consist of uppercase and lowercase English letters.
Follow up: Could you find an algorithm that runs in O(m + n) time?
分析
題目要求:
- 從字串s中擷取一段子字串ss
- ss內要包含字串t內的所有字元(s、t僅含有大小寫英文)
- 若t包含重複字元,例如兩個a,則該子字串(ss)中也必須有至少兩個a
- 若有多個可能的答案,求最短的(題目保證只有一個最短的)
在追加的要求中,提示了存在時間複雜度為 O(m+n) 的答案(m、n分別為s、t的長度)
由於題目要求一個一次方時間,代表我們要找尋一個簡單遍歷t與s便能求解的方法。
不如先試試貪心算法
貪心算法不就是一種時間複雜度為 O(n) 的策略嗎?從這個角度出發,想想這題要如何貪心?
從字串s的開頭出發,直到找到t中的所有字母便停止,並且再度從開頭出發,如果並不是t所要的字母便刪除。
舉個例子:(稍微修改Example 1.的測資以便教學)
t = 'ABC'
s = 'ZADOBECODEBANC'
從S的開頭出發
'ZA' 有 1A 0B 0C
'ZAD'
'ZADO'
'ZADOB' 有 1A 1B 0C
'ZADOBE'
'ZADOBEC' 有 1A 1B 1C
'ADOBEC' 因為不需要Z 從頭開始將其刪除,讓答案更短
透過這個策略,很容易便找到一個符合題目要求的子字串。
但這並不是最短的,因為我們很容易發現,最短且含有A、B、C的子字串應該是 s 最結尾的 ‘BANC’
貪心法給了一個正確的答案,但並不是最短的答案。
連續的貪心?那就是Sliding Window!
那如果我們試著「繼續使用貪心法」,來對後面的字串求解呢
在我們找到’ADOBEC’之後,如果故意捨棄掉開頭的A,這時的子字串就變回「少一個A」的狀態。於是我們可以持續往後找,直到下一個A出現為止:
'ZA' 有 1A 0B 0C
'ZAD'
'ZADO'
'ZADOB' 有 1A 1B 0C
'ZADOBE'
'ZADOBEC' 有 1A 1B 1C
'ADOBEC' 有 1A 1B 1C <-- 答案候補
'DOBEC' 有 0A 1B 1C <-- 故意刪掉A
'DOBECO' ...繼續找
'DOBECOD'
'DOBECODE'
'DOBECODEB'
'DOBECODEBA' 找到A
'OBECODEBA' 刪掉前面不必要的DO
'BECODEBA' 1A 2B 1C 這個B也不是必要的,可以繼續刪!
'ECODEBA'
'CODEBA' 1A 1B 1C <-- 答案候補
'ODEBA' 1A 1B 0C <-- 故意刪掉C
'ODEBAN'
'ODEBANC' 找到C
'DEBANC' 刪掉前面的...
'EBANC'
'BANC' <-- 答案候補
至此,我們找到了三組可能為最短的答案候補:
‘ADOBEC’、‘CODEBA’、‘BANC’
並且取其中最短的’BANC’作為最終的答案。
從說明的過程可以發現,我們在s中由左而右求子字串的每一個步驟,就像一扇窗戶從左「滑」到右,並且窗戶中「框著」的就是我們在該步驟中討論的字串。
這套策略,也因此被命名為Sliding Window
Sliding Window的時間複雜度?
這個策略的時間複雜度是多少呢?
-
在窗戶「由左往右滑」的過程,一共移動了多少次?
從上述的舉例中可以發現,每一個步驟必定是以下兩者之一:
窗戶的左邊界往右移動1 或者 窗戶的右邊界往右移動1
也就是說,總步驟最多為 2 * len(s) 即 O(n)
-
在每一個步驟中,統計「窗戶內」字串是否滿足要求的時間複雜度為多少?(Counting的時間複雜度)
你可能會想:窗戶最大的寬度為len(s),我要去計算每個字母出現的次數,所以每個「窗戶內」的字元都要去數一次,因此為 O(n)
實際上,sliding Window應用在Counting時,時間複雜度為O(1)
怎麼做到的?
只考慮通過邊界的字元(進/出Window),對Counting進行優化
在每個步驟中,由於Window左右邊界的改變,都會有一個字元進入或者離開Window
不重新統計整個Window,而是將Window內原本的字元數進行統計,並且當一個字元進入窗戶,便對其計數+1;反之當字元離開窗戶,便對其計數-1
以這種方式處理,counting部分的時間複雜度便為O(1)
整個Sliding Window的複雜度也就是O(n) x O(1) = O(1)
接下來,讓我們思考如何以程式碼來實現Sliding Window演算法
解題思路:Sliding Window + Hashmap
需求分析
將前述的策略代碼化,要考慮以下幾個問題:
-
如何設定窗戶與移動窗戶?
這很簡單,利用字串的index設定左右邊界為[left, right)
則 s[left:right] 即為我們當下討論的子字串。
移動窗戶,則考慮左右邊界的移動: 右邊界 right 從 1 移動至 len(s) 左邊界 left 從 0 移動至 lrn(s-1)
-
如何判斷窗戶內的子字串 是否滿足題目要求?
一個簡單的思維是,我對t和窗戶內的子字串ss分別進行字元別的統計,亦即,記錄下有幾個A幾個B幾個C ….然後再一一去比較ss的每個字元數量是否滿足t的字元數量。
不過這又產生一個新的問題:
在sliding Window的每個階段,都需要比對所有的’A’~‘Z’、‘a’~‘z’,一共比對52次!
既然每個步驟中,進出Window的字元只有一個,如果我們將前一次的比對結果以某種方式記錄下來,其實只需要重新比對「進出的這個字元」的數量,而不必比對所有字元的數量!
對「ss已滿足t的字元數種類」也同步進行Sliding Window Counting
這個第二層的Sliding Window Counting思維也正是本題美妙之處。
也因此題目特別做出了線性時間的提示,就是希望我們能思考到這一層。因為儘管O(52n) = O(n),未優化的時間常數還是大了很多!
實作的方法如下:
-
對t、ss進行字元數統計 (使用Python 的 dict)
-
以 goal 代表 t出現的字元種類數
-
以 score 紀錄 ss 滿足 t 的字元種類數
例如下例
t = 'ABBC' 1A 2B 1C goal = 3 (共有「3種」字元數量需要滿足) ss = 'ADB' 1A 1B 0C score = 1 (只有A的數量滿足t的要求) -
以l+1, r+1 作為window (ss = s[l+1, r+1])
-
移動右邊界,讓下一個字元進入Window [使用for迴圈從1~len(s)]
-
當新的字元進入Window,例如下一個字元是’C’,則
- 更新ss中’C’的字元數統計
- 比對ss與t的’C’的字元數統計
- 如果兩者此時恰好相同(代表原本ss的’C’不滿足t,但現在滿足了),代表多一種字元比對成功了。把 score+1
- 如果此時score == goal,代表ss現在完全滿足t。把此時的ss列為答案候補。
-
發現了一個答案候補時,便移動左邊界,將ss最前面的字元移出Window。假設其為’A’:
-
更新ss中’A的字元數統計’
-
比對ss與t中的’A’的字元數統計
-
如果ss中的’A’少於t中的’A’,則把score -1
因為我們是在score == goal(找到答案候補)時才開始將字元移出窗戶,所以原本(移出前)ss中的’A’必定滿足t,而現在(移出後)不滿足了,所以將score-1。
-
重新判定是否為答案候補。
[整個步驟7用while迴圈執行]
-
Python3 實作(雙Sliding Window + Hashmap):
from collections import defaultdict as dd # [見補充1]
class Solution:
def minWindow(self, s: str, t: str) -> str:
target, window = dd(int), dd(int) # 1. 使用dict 對t、ss進行字元數統計
for c in t: # 統計t的字元數
target[c] += 1 # 2. goal為t的「字元種類」數
score, goal = 0, len(target) # 3. score為ss滿足t的種類數
l = -1 # 4. 以s[l+1:r+1] 作為 Window
ansl = float('inf') # ansl 為候補字串中最短者的長度
# 5. 從l=-1, r=0 開始滑窗。
for r, rchar in enumerate(s): # 6. s[r]進入窗戶
if rchar in target: # 若 t 包含 s[r]
window[rchar] += 1 # 則將 s[r]的計數+1
if window[rchar] == target[rchar]: # 並比對 ss與t 中分別有幾個 s[r]
score += 1 # 若恰相同則 score+1
while score == goal: # 7. 若Window內的子字串為答案候補
l += 1 # 將ss的字首出窗(左邊界l+1)
lchar = s[l] # s[l]被移出窗戶
if lchar in target: # 若 t 包含 s[l]
window[lchar] -= 1 # 將s[l]的計數-1
if window[lchar]<target[lchar]: # 若此時s[l]的計數不滿足t
# [見補充2]
if r-l < ansl: # 答案候補 與 目前為止最短的答案候補 比較長度
ans,ansl = (l,r+1),r-l+1# 若更短,則更新答案與答案長度
score -= 1 # 並將score-1
return '' if ansl == float('inf') else s[ans[0]: ans[1]]
代碼的幾個補充:
-
這邊使用Pyyhon collections 模組中定義的 defaultdict 來取代 dict
因 Python 對 dict 取一個不存在的 key 時會報錯,這導致我們每次對 target 與 window 取值之前都要判空,很是麻煩。
defaultdict 在對不存在的 key 取值時會呼叫我們設定的函式來給預設值,我們這裡設定int(),也就是給0。如此一來便不須判空。
-
我們找到一個答案候補時(進入while迴圈時),並不馬上判斷其長度是否為更短的答案。
從代碼上可以發現,筆者是在 if window[lchar]<target[lchar]: 的block中才去判斷。
這邊的小優化在於,原本我們找到的答案候補,前面是可能有冗餘字的。例如
target = 'ABC' ss = 'DEABNC'我們很確定前面的DE是不必要的,且接下來會(隨著while迴圈持續迭代)陸續出窗。
那怎樣的ss才是真正的答案候補呢?從這個例子來看非常顯然,也就是當’A’也要出窗的時候
ss = 'ABNC'這時的ss便已是局部最短。
對應在代碼上,就是即將要離開這個while迴圈前的最後一個ss,也就是在我們把score-1的時候的窗戶內的東西。這時再做判定即可。
這樣的作法可以優化一點點的時間常數。
-
本例採用一邊滑窗一邊判定答案候補的作法。代碼稍嫌冗長。
如果想要簡潔的代碼,也可以拿一個list儲存所有的答案候補,並在最後篩選出長度最短者作為答案。
(但本解會增加空間複雜度,詳見次段)
from collections import defaultdict as dd class Solution: def minWindow(self, s: str, t: str) -> str: target, window = dd(int), dd(int) for c in t: target[c] += 1 score, goal = 0, len(target) l = -1 ans = [] for r, rchar in enumerate(s): if rchar in target: window[rchar] += 1 if window[rchar] == target[rchar]: score += 1 while score == goal: l += 1 lchar = s[l] if lchar in target: window[lchar] -= 1 if window[lchar] < target[lchar]: ans.append(s[l:r+1]) score -= 1 return min(ans, key=len, default='')
複雜度分析
時間複雜度 T = O(m+n),m、n分別為s、t的長度
建置counting的dict時,遍歷了整個t,時間複雜度為O(n)
sliding window演算法的過程中,左右邊界最多均遍歷整個s,時間複雜度為O(2m) = O(m)
因此,整個答案的時間複雜度為O(m+n)
空間複雜度 S = O(1)
代碼中被儲存下來的東西只有:target、window、score、goal、ansl、ans
其中target、window兩個dict最多儲存52組value-pair
其餘的變數均為primitive variable
因此空間複雜度可視為O(1)
將所有答案候補儲存下來的空間複雜度 S = O(m^2)
若將所有答案候補儲存下來,需要儲存幾個答案?
由前一段的討論可知,筆者的解法只有在s[l]出窗的時候(左邊界l移動時)會得出一個答案候補
因此答案候補最多有 m = len(s)個
每個答案候補有多長? 其最長可能為 m = len(s)
雖然兩者的極值必定不會同時發生,但大致上仍可用 O(m^2) 來表示。
Leetcode Submissions
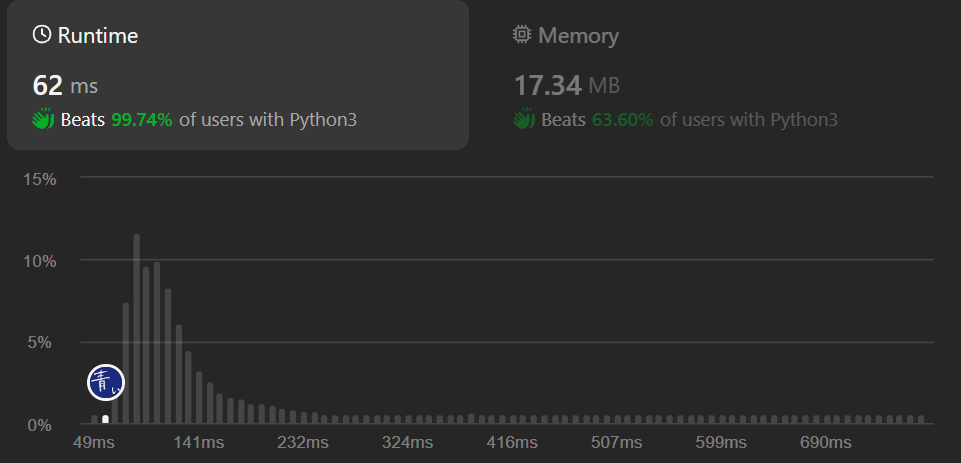

結語
解這題的過程,筆者一開始糾結於如何在O(m+n)的複雜度限制下去比對52個大小寫英文字母,後來想到可以針對匹配數再做一層的sliding window後才茅塞頓開。
第一層的counting是顯式的,第二層對counting的結果的匹配數再進行counting則是隱式的。很喜歡這種觀察到自己的思考更加抽象化的瞬間。
感謝你的閱讀,如果有不同的想法或心得,歡迎留言一同討論!